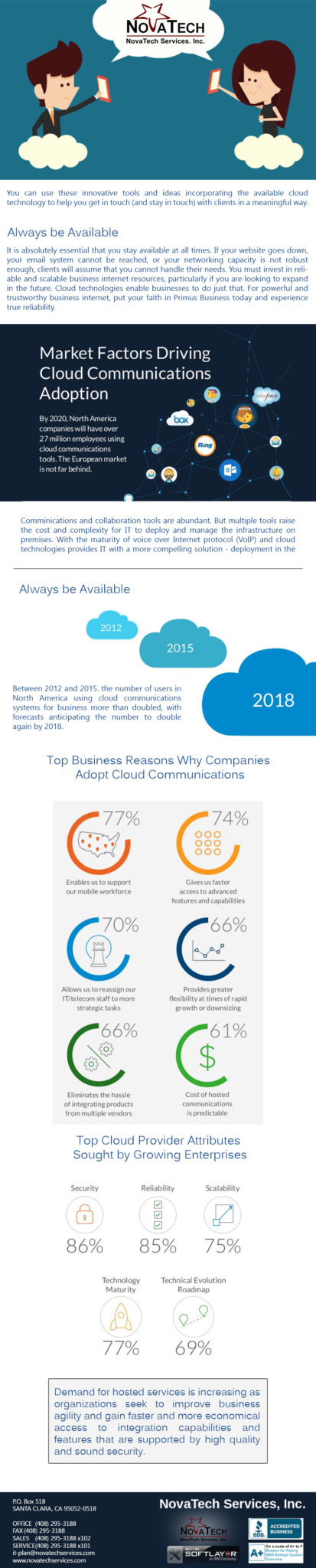
Semantics: “Public,” “Private,” and “Hybrid” in Cloud Computing, Part II
Welcome back! In the second post in this two-part series, we’ll look at the third definition of “public” and “private,” and we’ll have that broader discussion about “hybrid”—and we’ll figure out where we go after the dust has cleared on the semantics. If you missed the first part of our series, take a moment to get up to speed here before you dive in.
Definition 3—Control: Bare Metal v. Virtual
A third school of thought in the “public v. private” conversation is actually an extension of Definition 2, but with an important distinction. In order for infrastructure to be “private,” no one else (not even the infrastructure provider) can have access to a given hardware node.
In Definition 2, a hardware node provisioned for single-tenancy would be considered private. That single-tenant environment could provide customers with control of the server at the bare metal level—or it could provide control at the operating system level on top of a provider-managed hypervisor. In Definition 3, the latter example would not be considered “private” because the infrastructure provider has some level of control over the server in the form of the virtualization hypervisor.
Under Definition 3, infrastructure provisioned with full control over bare metal hardware is “private,” while any provider-virtualized or shared environment would be considered “public.” With complete, uninterrupted control down to the bare metal, a user can monitor all access and activity on the infrastructure and secure it from any third-party usage.
Defining “public cloud” and “private cloud” using the bare metal versus virtual delineation is easy. If a user orders infrastructure resources from a provider, and those resources are delivered from a shared, virtualized environment, that infrastructure would be considered public cloud. If the user orders a number of bare metal servers and chooses to install and maintain his or her own virtualization layer across those bare metal servers, that environment would be a private cloud.
Source: http://blog.softlayer.com/2015/semantics-public-private-and-hybrid-cloud-computing-part-ii