Make the cloud work for you



While the importance of choosing the right disaster recovery solution and cloud provider cannot be understated, having a disaster recovery runbook is equally important (if not more). I have been involved in multiple conversations where the customer’s primary focus was the implementation of the best-suited disaster recovery technology, but conversation regarding DR runbook was either missing completely or lacked key pieces of information. Today, my focus will be to lay out a frame work for what your DR runbook should look like.
“Eighty percent of businesses affected by a major incident either never re-open or close within 18 months.” (Source: Axa Report)
What is a disaster recovery runbook?
A disaster recovery runbook is a working document that outlines a recovery plan with all the necessary information required for execution of this plan. This document is unique to every organization and can include processes, technical details, personnel information, and other key pieces of information that may not be readily available during a disaster situation.
What should I include in this document?
As previously stated, a runbook is unique to every organization depending on the industry and internal processes, but there is standard information that applies to all organizations and should be included in every runbook. Below is a list of the most important information:
Source : http://blog.softlayer.com/2016/disaster-recovery-cloud-are-you-prepared

As a SoftLayer sales engineer, I get the opportunity to talk to a wide range of customers on a daily basis about almost everything under the sun. This is one of my favorite parts of working at SoftLayer: every day is unique and the topics range from a standalone LAMP server to thousands of servers in a big data cluster—and everything in between. It can be challenging at times, due to the infinite number of solutions that SoftLayer can run, but it also gives me the chance to learn and teach others. In this blog post, I’ll discuss high availability (HA), disaster recovery (DR), global server load balancing (GSLB), and load balancing (LB), as I occasionally hear customers mix up the terms, and I think a little clarity on the topics could help.
Before we dive into the differences, let’s define each in alphabetical order (I did take a stab at stating this in my own words, but Wikipedia does such a good job that I paraphrased from its descriptions and added in a little more context).
Now that we’ve defined each of these topics, let’s quickly check off the main points of each topic:
HA
Hardware Recommendations
Source : http://blog.softlayer.com/2016/ha-dr-gslb-lb-what%E2%80%99s-what-and-who%E2%80%99s-who-uptime
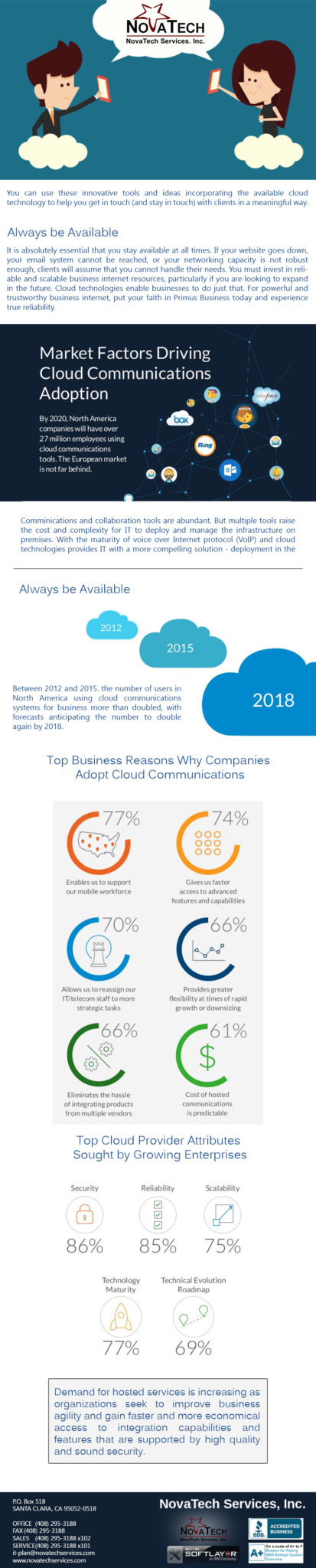
Whatever your opinion is of IBM Cloud, the company has made tangible strides to provide a compelling hybrid cloud strategy for the enterprise. Several analysts even recently acknowledged IBM leadership in this area. Based on the recent announcement with VMware, you’ll understand why existing VMware clients are pretty excited about IBM Cloud’s hybrid strategy.
The announcement notes that SoftLayer provides the capability to create secure and flexible VMware environments on top of IBM’s public cloud—now with expanded (and cost-effective) capabilities. These capabilities allow existing VMware customers to:
IBM Cloud encompasses a much larger scope that includes native SoftLayer and open source options, Bluemix/PaaS, as well as extensive cloud solutions and services.
The following are VMware-related FAQs, in addition to the ones you can find on KnowledgeLayer:
Why can’t I do “lift and shift” on other cloud platforms, e.g., AWS or Microsoft Azure?
In simple terms, you’ll need access to the virtualization host in order to “fully” operate your VMware environment (as you’d be used to it from your own data center). Neither AWS nor Azure allows you this level of control; they also run different hypervisors. SoftLayer allows you to deploy and manage physical hosts in addition to standard virtual servers.
Why would I do “lift and shift” on SoftLayer and not on VMware’s own public cloud?
Performing the extension on SoftLayer lets you:

Did you know that you can complement your SoftLayer infrastructure with IBM Bluemix platform-as-a-service? (Read on—then put these ideas into practice with a special offer at the end.)
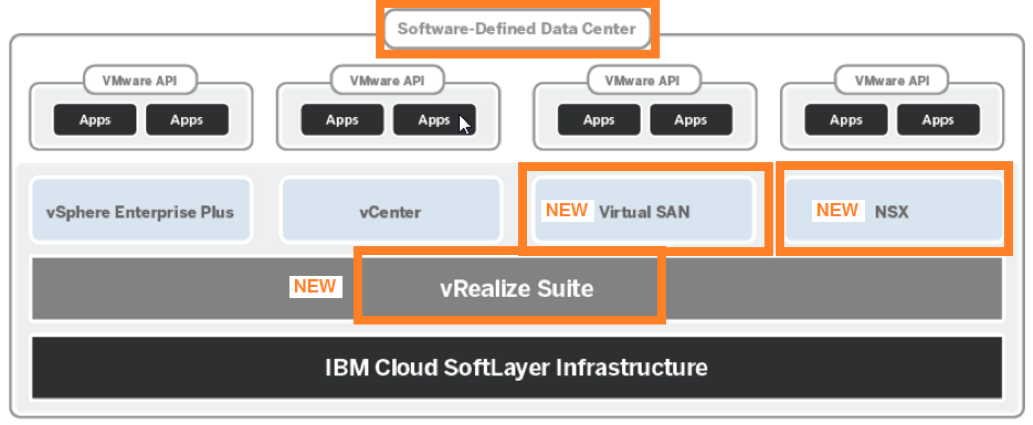
When you pair Bluemix with SoftLayer, you can buy, build, access, and manage the production of scalable environments and applications by using the infrastructure and application services together.
Whether you need insight on the effectiveness of a multimedia campaign, need to process vast amounts of data in real-time, or want to deploy websites and web content for millions of users, you can create a better experience for your customers by combining the power of your SoftLayer infrastructure with Bluemix.
Bluemix solutions and services allow you to:
You can see the value of an integrated SoftLayer/Bluemix experience by looking at insights and cognitive, big data and analytics, and web applications.
Source: http://blog.softlayer.com/2016/meet-integrated-ibm-cloud-platform-softlayer-and-bluemix
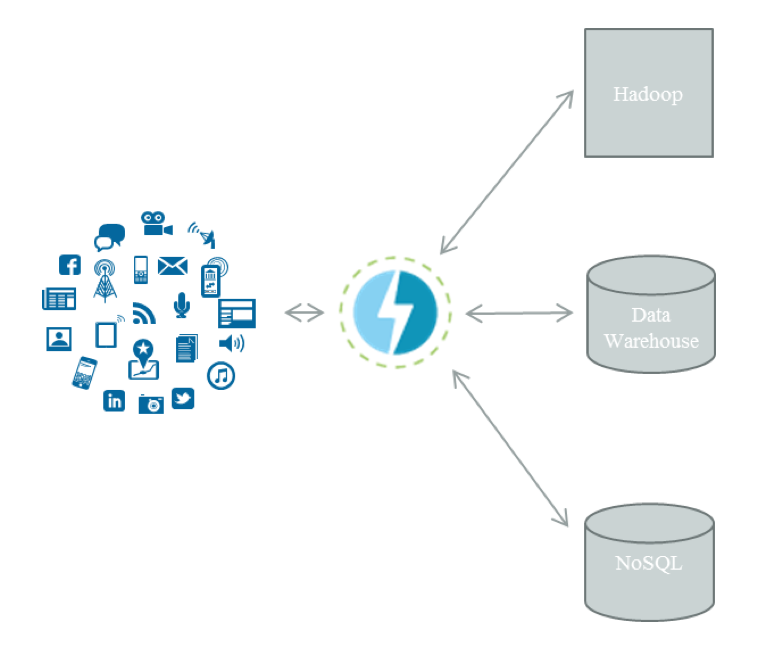
Direct server return (DSR) is a load balancing scheme that allows service requests to come in via the load balancer virtual IP (VIP). The responses are communicated by the back-end servers directly to the client. The load is taken off the load balancer as the return traffic is sent directly to the client from the back-end server, bypassing it entirely. You may want to do this if you have larger files to be served or traffic that doesn’t need to be transformed at all on its way back to the client.
Here’s how it works: Incoming requests are assigned a VIP address on the load balancer itself. Then the load balancer passes the request to the appropriate server while only modifying the destination MAC address to one of the back-end servers.
You need to be aware of the following when using DSR:
Source : http://blog.softlayer.com/2016/use-dsr-take-load-your-load-balancer